
某个业务需要让用户下载文件盖章之后重新上传盖章版本,但是现在有个问题那就是操作基本都在手机端,通过手机端上传 pdf 的确是个问题。所以目前的方案是上传盖章版之后的图片。
然鹅,这个方法用户表示略微有点蛋疼,有的需要上传几十张图片,这些盖章的图片重新下载之后管理也是个问题。那个是哪个根本分不清楚,并且要想根据业务编号来管理盖章版文件也是个问题。
所以,就给出了一个方案,将上传的 图片重新转换为 pdf。
鉴于图片是放在 oss 上的,oss 本身倒是提供了图片转 pdf 的方法(https://help.aliyun.com/zh/imm/user-guide/convert-an-image-to-pdf):
# -*- coding: utf-8 -*-
# This file is auto-generated, don't edit it. Thanks.
import sys
import os
from typing import List
from alibabacloud_imm20200930.client import Client as imm20200930Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_imm20200930 import models as imm_20200930_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_tea_util.client import Client as UtilClient
class Sample:
def __init__(self):
pass
@staticmethod
def create_client(
access_key_id: str,
access_key_secret: str,
) -> imm20200930Client:
"""
使用AccessKey ID&AccessKey Secret初始化账号Client。
@param access_key_id:
@param access_key_secret:
@return: Client
@throws Exception
"""
config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret
)
# 填写访问的IMM域名。
config.endpoint = f'imm.cn-zhangjiakou.aliyuncs.com'
return imm20200930Client(config)
@staticmethod
def main(
args: List[str],
) -> None:
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过从环境变量中读取AccessKey,来实现API访问的身份验证。如何配置环境变量,请参见https://help.aliyun.com/document_detail/2361894.html。
imm_access_key_id = os.getenv("AccessKeyId")
imm_access_key_secret = os.getenv("AccessKeySecret")
client = Sample.create_client(imm_access_key_id, imm_access_key_secret)
sources_0 = imm_20200930_models.CreateImageToPDFTaskRequestSources(
uri='oss://test-bucket/test-object.jpg'
)
create_image_to_pdftask_request = imm_20200930_models.CreateImageToPDFTaskRequest(
project_name='test-project',
target_uri='oss://test-bucket/test-target-object.pdf',
sources=[
sources_0
]
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印API的返回值。
client.create_image_to_pdftask_with_options(create_image_to_pdftask_request, runtime)
except Exception as error:
# 如有需要,请打印错误信息。
UtilClient.assert_as_string(error.message)
@staticmethod
async def main_async(
args: List[str],
) -> None:
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过从环境变量中读取AccessKey,来实现API访问的身份验证。如何配置环境变量,请参见https://help.aliyun.com/document_detail/2361894.html。
imm_access_key_id = os.getenv("AccessKeyId")
imm_access_key_secret = os.getenv("AccessKeySecret")
client = Sample.create_client(imm_access_key_id, imm_access_key_secret)
sources_0 = imm_20200930_models.CreateImageToPDFTaskRequestSources(
uri='oss://test-bucket/test-object.jpg'
)
create_image_to_pdftask_request = imm_20200930_models.CreateImageToPDFTaskRequest(
project_name='test-project',
target_uri='oss://test-bucket/test-target-object.pdf',
sources=[
sources_0
]
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印API的返回值。
await client.create_image_to_pdftask_with_options_async(create_image_to_pdftask_request, runtime)
except Exception as error:
# 如有需要,请打印错误信息。
UtilClient.assert_as_string(error.message)
if __name__ == '__main__':
Sample.main(sys.argv[1:])
然而,项目里面已经引入了比较旧的 aliyun 的 sdk。这个新的再引用之后就需要修改之前的代码,这也就蛋疼了。
网上搜了一下,代码不少,但是不好用啊,这尼玛,就没人写个靠谱的代码吗?
最终通过PyMuPDF来解决了这个问题:
import fitz # PyMuPDF
# Open an existing PDF or create a new one
pdf_document = fitz.open() # Creates a new PDF
# Define the image file path
image_path = "path/to/your/image.jpg"
# Get the dimensions of the image
img = fitz.open(image_path)
img_rect = img[0].rect # Get the rectangle of the first page of the image
# Create a new page with the same dimensions as the image
pdf_page = pdf_document.new_page(width=img_rect.width, height=img_rect.height)
# Insert the image into the new page
pdf_page.insert_image(pdf_page.rect, filename=image_path)
# Save the PDF to a file
pdf_document.save("output.pdf")
pdf_document.close()
实际的业务代码:
def converImageToPdf(img_list):
# pdf = fitz.open() # PyMuPDF
pdf_document = fitz.open() # Creates a new PDF
for img_url in img_list:
img_local_file = download_image(img_url,'confirmd_images')
img = fitz.open(img_local_file)
img_rect = img[0].rect # Get the rectangle of the first page of the image
# Create a new page with the same dimensions as the image
pdf_page = pdf_document.new_page(width=img_rect.width, height=img_rect.height)
# Insert the image into the new page
pdf_page.insert_image(pdf_page.rect, filename=img_local_file)
img.close()
file_name = random_file_name('pdf')
if not os.path.exists('confirmd_receipt'):
os.mkdir('confirmd_receipt')
pdf_document.save(os.path.join('confirmd_receipt/') + file_name)
pdf_document.close()
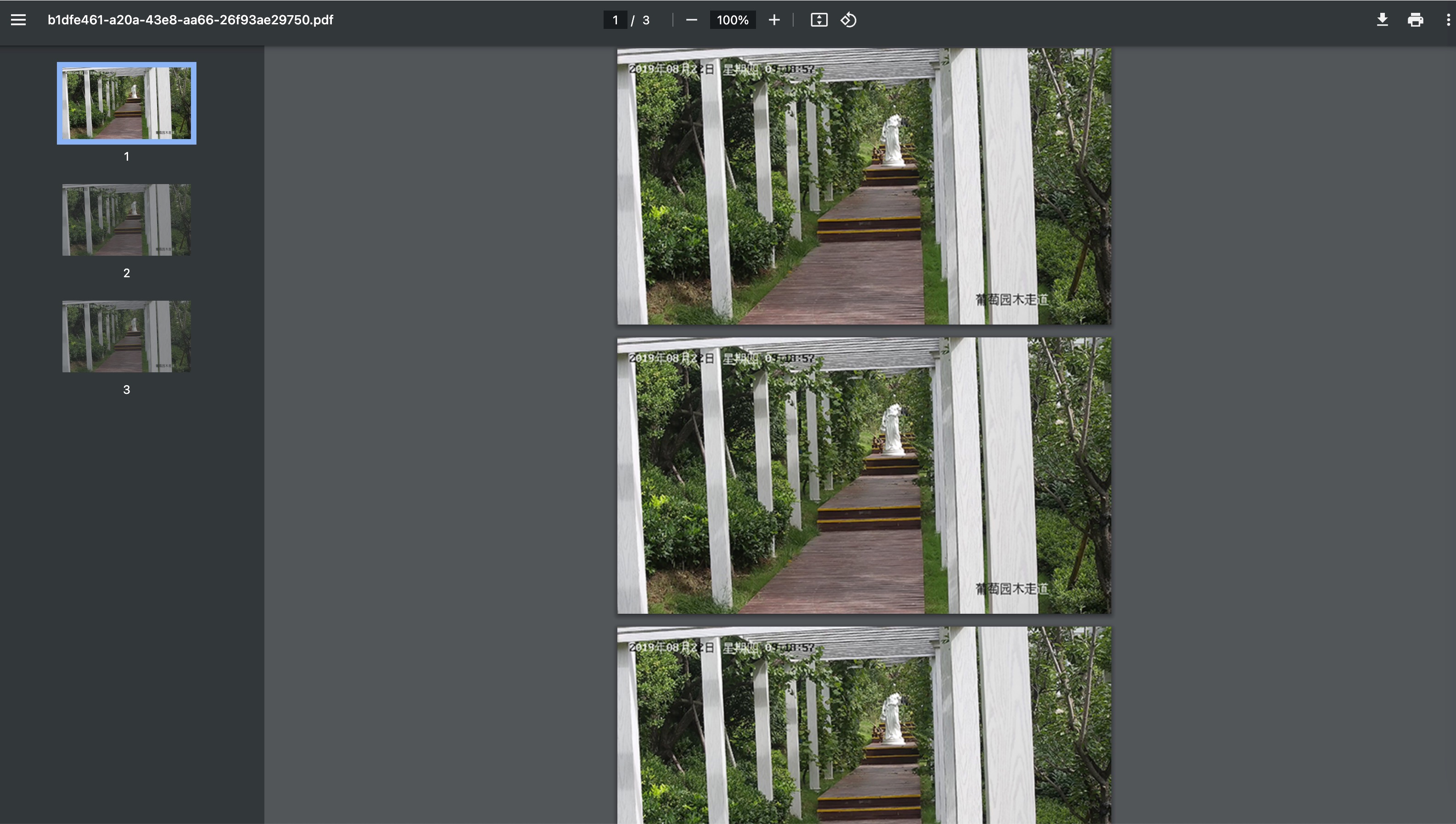
实际效果:
依赖:
PyMuPDFb == 1.24.9
31 comments
专业。
看得我也想学一下python,用来应负一下平时简单的自动化需求。就是担心自己学不来
用来做自动化还是蛮方便的
高级,但用不上哎~
没关系,我也是记录一下,作为备忘录。😂
PC端一直用Acrobat,蛮方便的;
移动端没这个需求,不知道pdf.js能否可以
这个主要是在服务器自动合并。
方法挺不错 但目前还用不上😂
说不定哪天就用上了 哈哈
可能如此吧 多一个方法始终是好的
是个好办法。
滴 先打卡
滴,老年卡
最近也是想学一门编程语言,不过还在 helloword 阶段,很多不懂、然后谷歌翻译的文档无法直视。
我也是静不下心学习。不然我准备用新的语言重写我那个易语言搞得静态博客生成器了。
想看了就看点,随时都能学
这个是部署在服务器上的?涉及公章与保密内容,还是用软件转换比较方便和安全
业务决定处理方式
牛逼,爱折腾的女程序员
活还得干啊
Python 被你玩的明明白白了,有些羡慕了
复制粘贴而已
不亏是我obaby姐,上的厅房,下得机房,能文能武,能Python
😂
wps可以直接用,下次有类似格式转化可以找我,我有会员 ,分分钟搞定
谢啦
这个东西不能手工搞,手工累死啦,😂
每天都有人上传。
是用原生应用做上传吗?安卓简单些,iOS比较麻烦。如果是在小程序里面的话就简单很多了,我最近做了一个发票上传,就是手机端传PDF,直接在微信小程序里面读取聊天记录中的PDF,然后做上传即可。
app 端上传
这也要写代码呀?要是我,我会下载下来,然后用万兴PDF直接合并
每天几百张图片,人工合并就 gg 了。
可是python的,java的就拿来参考下
来吧,转 python
可以试试手机相册自带的功能,我是小米,直接选择需要的照片,然后生成 pdf